快照读
单纯的select操作,不包括上述 select … lock in share mode, select … for update。 Read Committed隔离级别:每次select都生成一个快照读。 Read Repeatable隔离级别:开启事务后第一个select语句才是快照读的地方,而不是一开启事务就快照读。
快照读的实现方式:undolog和多版本并发控制MVCC
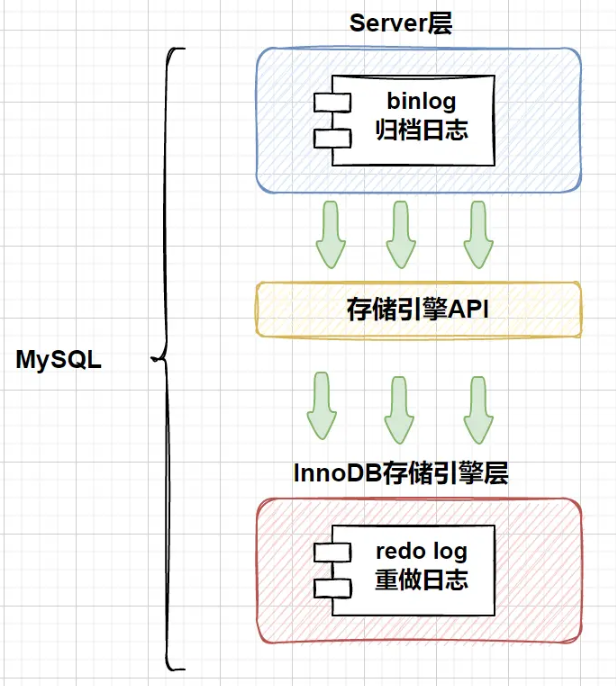
下图右侧绿色的是数据:一行数据记录,主键ID是10,name=‘Jack’,age=10, 被update更新set为name= ‘Tom’,age=23。
事务会先使用“排他锁”锁定改行,将该行当前的值复制到undolog中,然后再真正地修改当前行的值,最后填写事务的DB_TRX_ID,使用回滚指针DB_ROLL_PTR指向undo log中修改前的行DB_ROW_ID。
 DB_TRX_ID: 6字节
DB_TRX_ID: 6字节DB_TRX_ID字段,表示最后更新的事务id(update,delete,insert)。此外,删除在内部被视为更新,其中行中的特殊位被设置为将其标记为已软删除。
DB_ROLL_PTR: 7字节回滚指针,指向前一个版本的undolog记录,组成undo链表。如果更新了行,则撤消日志记录包含在更新行之前重建行内容所需的信息。
DB_ROW_ID: 6字节的DB_ROW_ID字段,包含一个随着新行插入而单调递增的行ID, 当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。如果表中没有主键或合适的唯一索引, 也就是无法生成聚簇索引的时候, InnoDB会帮我们自动生成聚集索引, 聚簇索引会使用DB_ROW_ID的值来作为主键; 如果表中有主键或者合适的唯一索引, 那么聚簇索引中也就不会包含 DB_ROW_ID了 。
其它:insert undolog只在事务回滚时需要, 事务提交就可以删掉了。update undolog包括update 和 delete , 回滚和快照读 都需要。
锁
锁与快照读区别
锁区间划分
间隙锁
实例:(3, 4)
间隙锁是开区间的,是一个在索引记录之间的间隙上的锁。
作用:保证某个间隙内的数据在锁定情况下不会发生任何变化。比如我mysql默认隔离级别下的可重复读(RR)。
当使用唯一索引来搜索唯一行的语句时,不需要间隙锁定。如下面语句的id列有唯一索引,此时只会对id值为10的行使用记录锁。
select * from t where id = 10 for update;// 注意:普通查询是快照读,不需要加锁
如果,上面语句中id列没有建立索引或者是非唯一索引时,则语句会产生间隙锁。 如果,搜索条件里有多个查询条件(即使每个列都有唯一索引),也是会有间隙锁的。 根据检索条件向下寻找最靠近检索条件的记录值A作为左区间,向上寻找最靠近检索条件的记录值B作为右区间,即锁定的间隙为(A,B),并且,不允许其他区间进行修改的值为查询的值
临键锁
临键锁是行锁+间隙锁,即临键锁是是一个左开右闭的区间,比如(- ∞, 1 ] |(1, 3 ] |(3, 4 ] | (4, + ∞)。 InnoDB的默认事务隔离级别是RR,在这种级别下,如果使用select … in share mode或者select … for update语句,那么InnoDB会使用临键锁,因而可以防止幻读;但即使你的隔离级别是RR,如果你这是使用普通的select语句,那么InnoDB将是快照读,不会使用任何锁,因而还是无法防止幻读。
隔离级别
读未提交
脏读
读已提交
不可重复读
可重复读
部分幻读: 使用当前读后会出现幻读,都使用快照读,或者都使用当前读可以避免幻读
串行化
资源占用大
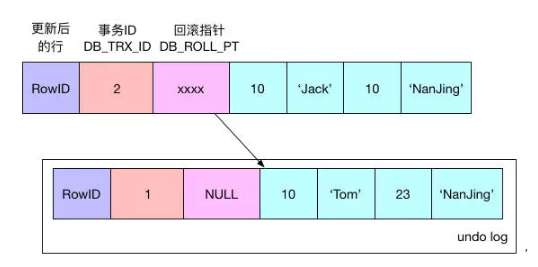
执行流程
连接器 → 缓存 → 分析器 → 优化器 → 执行器
详情
SQL执行顺序
from → on → join → where → group by → having → select → distinct → order by → limit
索引
B+树索引
结构
首对比各类树结构
树结构对比
B+树只有叶子节点才会存放数据,好处是IO次数变少,有利于范围搜索
二叉查找树: 左子节点永远比自己小,又子节点永远比自己大 缺点:层数大,io次数多,会有单链表情况
平衡二叉树: 在二叉树的基础上要求每个节点的子节点高度相差不能超过1
B树: 单个节点可以存储多个键值和数据的平衡树,高度降低,减少IO次数
B+树: 叶子节点存储数据,非叶子节点只存储键值.因为innodb中的页默认大小是16kb,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快。一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
②因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。
模式
聚集索引:
以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+ 树的叶子节点中,存储了表中所有的数据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
非聚集索引(非聚簇索引):
以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。
sql优化
1.优化原则 2.优化方法 3.debug方法
LOG

undolog:
用于事务回滚,当一个事务开始时,就需要记录undolog。事务提交成功由redolog保证数据持久性,而事务可以进行回滚从而保证事务操作原子性则是通过undolog 来保证的。
1. 在Mysql里数据每次修改前,都首先会把修改之前的数据作为历史保存一份到undolog里面的,数据里面会记录操作该数据的事务ID,然后我们可以通过事务ID来对数据进行回滚。
redolog:
是用于保证事务的持久性,在事务提交时写入。
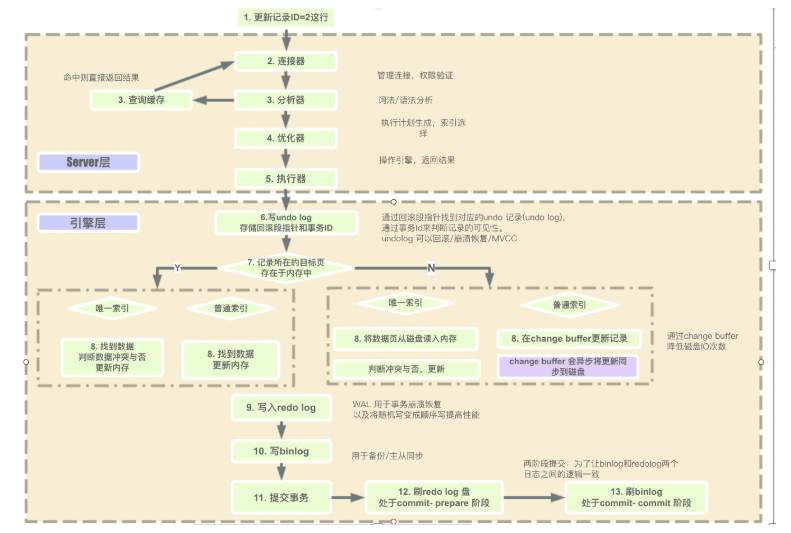
1.redolog(重做日志)是InnoDB存储引擎独有的,它让MySQL有了崩溃恢复的能力。InnoDB存储引擎为redo log的刷盘策略提供了innodb_flush_log_at_trx_commit参数,它支持三种策略:0,2都会有1s的数据损失。
- 0:设置为0的时候,每次提交事务时不刷盘。
- 1:设置为1的时候,每次提交事务时刷盘。
- 2:设置为2的时候,每次提交事务时都只把redo log buffer写入page cache。
binlog:
binlog是MySQL的二进制日志文件。
1. delete没加where条件?不慌!binlog可以帮你恢复数据
2. 搭建一套一主两从的MySQL集群,binlog帮你完成主从的数据同步
3. 分析日志